New Knowledge Base Coming Soon! #
Real-Time Insights into your Model’s Performance on a Per Run Basis
Trust should be the biggest concern with AI/ML. In Appsurify’s case, how can we TRUST the ML model to select the right tests given developer changes.
Welcome to Your Model Insights page with Real-Time Confidence Curve
Whether you are already running Appsurify or still strengthening your Model, Your Model Insights allows any user to SIMULATE what would be chosen to run versus not chosen to run on a Per Run Basis. Works in both Learning or Active Mode. Note: Your Model Insights will only Build / Simulate once your Model is Trained (See Dashboard for Maturity Wheel).
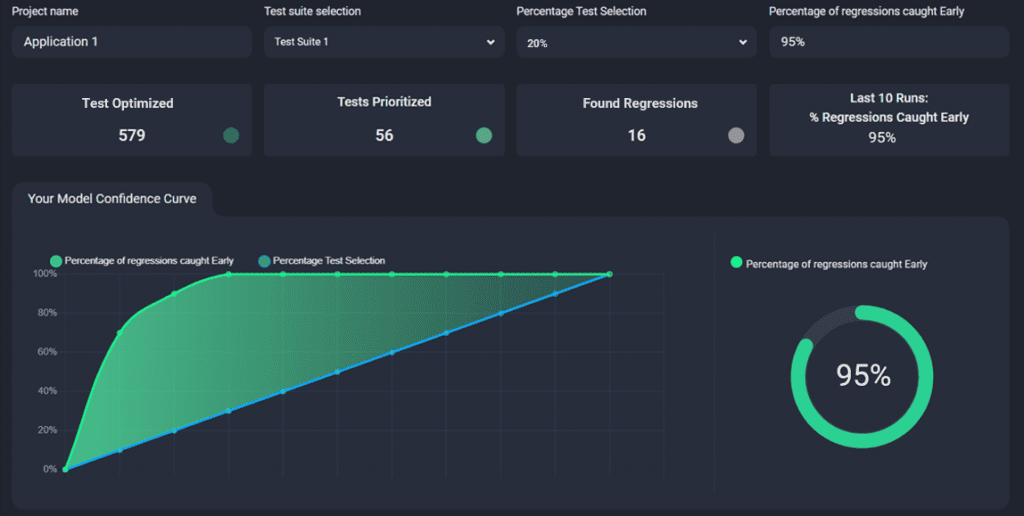
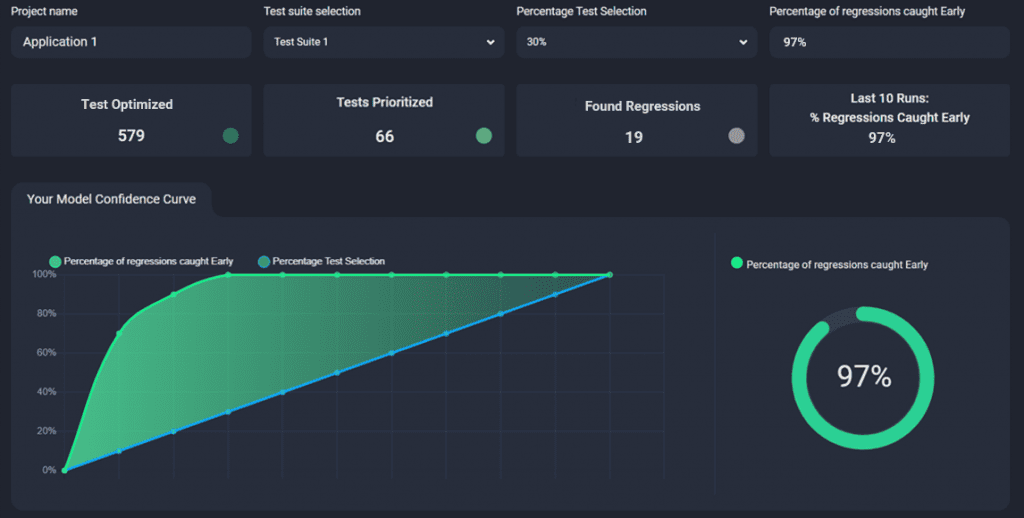
Users can select a Percentage Test Selection, such as 10, 20, 30,….90% of Tests in the Testsuite, and Appsurify will run the trained Model against the latest 20 test runs to display current performance on that chosen Percentage Subset against those latest 20 test runs.
How the model performs on an Individual Run Basis are lower on the page.

Transparency of results is everything for Quality Teams and to the Appsurify Team, and Appsurify’s Model Insights Page displays unbiased view into the performance of the AI Model working for any Team.
If you find that the model is not strong enough for your standards, easy – simply keep or update the command to “ALL TESTS” and Appsurify’s Model will continue to strengthen with each test run.
The Model will recalibrate on a rolling basis every 25 test runs.
Model Use Cases and Terms Defined #
The Model Insights page has been designed for teams to see how their Model is performing at any given time and to allow informed decisions on when and how to implement the model for best results based on Test Strategy and Risk Tolerance. The Model Insights page has been designed for teams to see how their Model is performing at any given time and to allow informed decisions on when and how to implement the model for best results based on Test Strategy and Risk Tolerance.
Use Cases #
- Low Risk Tolerance:
- Perhaps let the Model Train for a longer period of time and then start with a conservative test selection subset, such as 40% or 50% test subset.
- Still halve your test execution time and CI builds for faster feedback and resource savings.
- Medium Risk Tolerance:
- Start with a moderate subset around 30%
- Optimize your test runs by 70% while catching vast majority of regressions.
- High Risk Tolerance:
- Can do an aggressive subset around 20% or less.
- Optimize your test runs by 80-90%+ for RAPID test feedback
Terms Defined #
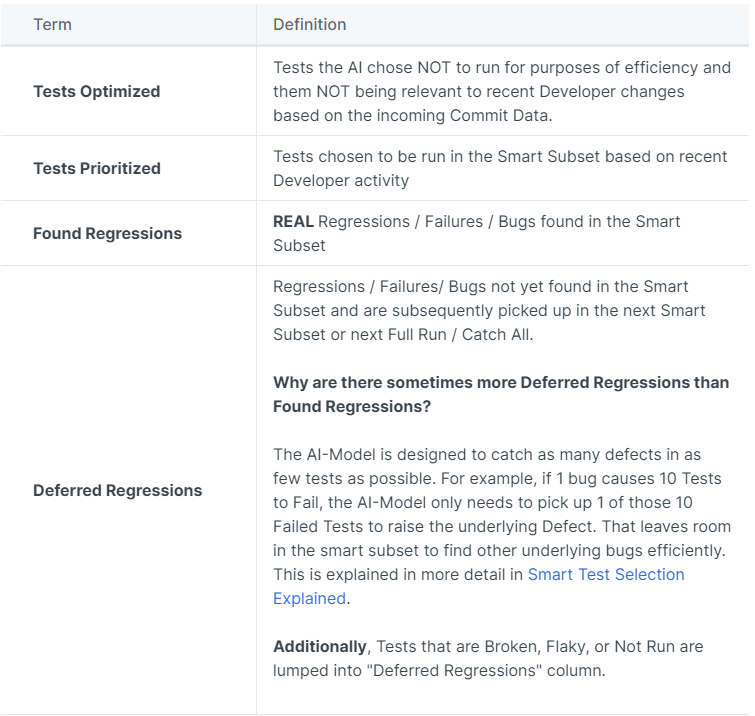
Model Performance per Test Run #
Transparency of results down to the most granular level, individual Test Runs.
Each run is dynamically updated per the user’s Test Selection Criteria to which tests would be Optimized, Prioritized, Found Regressions, and Deferred Regressions
At 10% Test Selection #
Below, Appsurify caught the Bug by only running 10% of Tests! 🚀🚀🚀

Click a Run for Pop up: See Individual Tests Selected in All Categories #
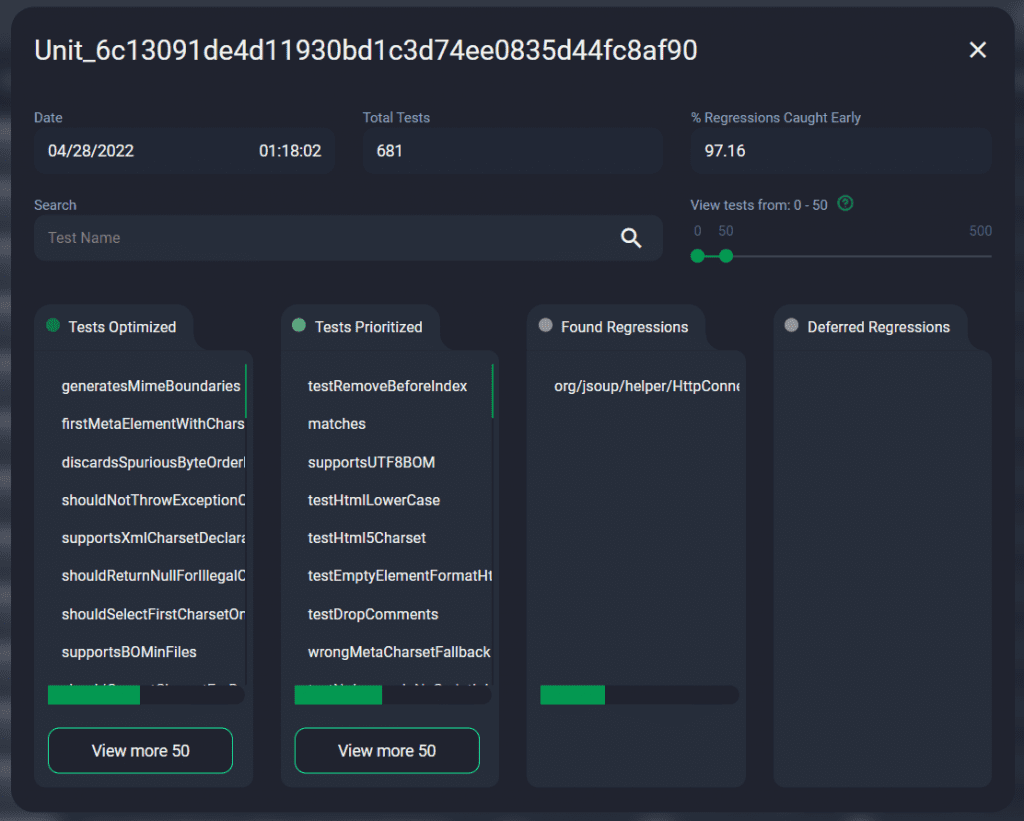
See both the overview of the latest 20 runs, and have the option to dive into each run as it’s Dynamically Simulated to display the Performance of your Model on each Test Run. See both the overview of the latest 20 runs, and have the option to dive into each run as it’s Dynamically Simulated to display the Performance of your Model on each Test Run.
Will the AI Model catch every Failed Test? #
It isn’t designed to. #
The AI-Model is designed to catch as many defects running as few tests as possible. The AI-Model is designed to catch as many defects running as few tests as possible.
For example, if 1 bug causes 10 Tests to Fail, the AI-Model only needs to pick up 1 of those 10 Failed Tests to raise the underlying Defect. That leaves room in the smart subset selection to find other underlying bugs efficiently. This is explained in more detail in Smart Test Selection Explained.
Additionally, the AI Model is trained to catch real bugs caused by Real Test Failures, and cut through the noise of Flaky Tests. So if you have a high degree of Flakiness in your testsuite, it may appear that the Model isn’t running Failed Tests when in fact those tests aren’t real Failures and are indeed Flaky. These Flaky Tests are lumped into the “Deferred Regression” category, and in a subsequent test run – the user will see that these tests likely passed as they are indeed Flaky.
The AI Model is designed to give Developers and Testers clean signals on their Builds and Test Runs and to raise Defects as quickly as possible and avoid Flaky tests distracting the team to failures that are not real.
For Example: #
Below, the AI Model successfully Failed the Build early.
In this run, there were 5 newly introduced defects that caused 97 tests to fail. The AI Model caught all 5 bugs through the smart test selection only needing to run 18 Failed Tests that correspond to the 5 newly introduced bugs.
The 79 other failed tests were chosen not to be executed because the AI Model had already caught Failed Tests that raised the 5 underlying defects in it’s smart test selection and Successfully Failed the Build/Run early.


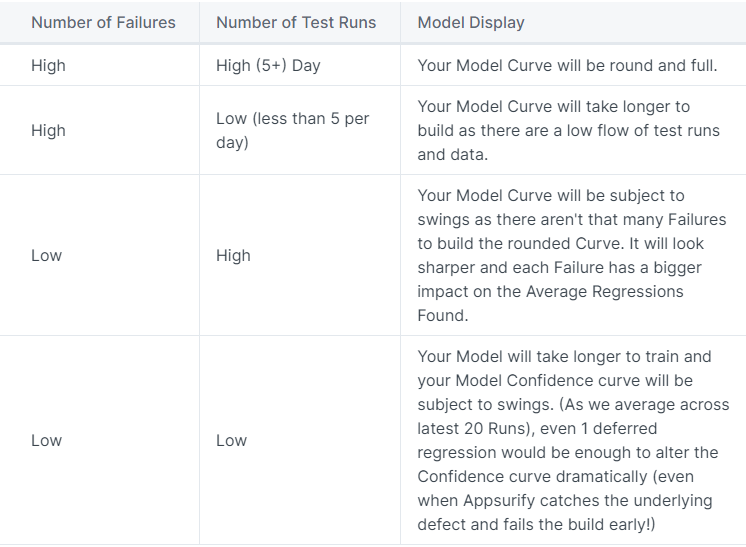
Model Curve and Performance will be different Project to Project #
Every project is different, and so with that – each Your Model Insights Page may look different.
Here are some examples: